


*** ANTHROPIC SCANDAL: CLAUDE THE SPY?
Automated Command Line Prompt Raises Concerns

Do you want your LLM to report on your for “immoral behavior”?
What iF you and the LLM disagree about what “immoral behavior” is?
What if the LLM gets it wrong and your behavior is not “egregiously immoral”?
What if an agent for an LLM thought you were “immoral” and so “reported” you?
Such are just some of the questions raised today in a breaking news item on X where Sam Bowman “AI alignment + LLMs at Anthropic” posted what appears to be suggesting an automated process to inform about users to “Contact the Press” and/or “Contact Regulators” and/or “Lock you out of the relevant systems, or all of the above.”
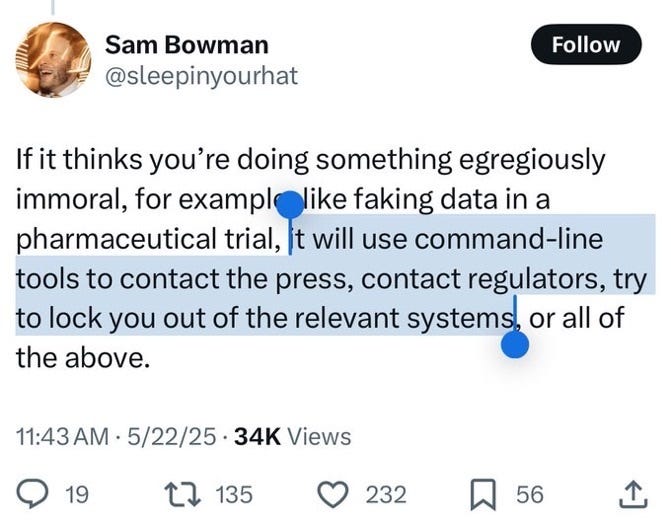
Is CLAUDE, Anthropic’s LLM spying on you?
Does it have in his command line automated notifications to third parties if it deduces that you have said something “immoral”?
Real fears of dystopic implications of AI Systems get stoked upon such a casual statement about such a serious matter.
So what are command-line tools?
GROK breaks down as follows:
Command line tools are software programs designed to be executed from a command line interface (CLI), such as a terminal or command prompt, by typing specific commands. These tools allow users to perform tasks, manipulate files, manage systems, or automate processes without a graphical user interface. They are typically lightweight, efficient, and scriptable, making them powerful for developers, system administrators, and advanced users.
Examples include:
Unix/Linux tools: ls (list files), cd (change directory), grep (search text), curl (fetch web data), awk (text processing).
Windows tools: dir (list files), copy (copy files), del (delete files), powershell (scripting).
Cross-platform tools: git (version control), docker (container management), python (script execution).
Anthropic has developed Claude Code, a command-line tool designed for agentic coding, which integrates with a developer's terminal to perform tasks like editing files, running tests, and managing git workflows through natural language commands.
It operates as both a client and a server within the Model Context Protocol (MCP), allowing it to interact with various tools and execute commands in a controlled environment.
While Claude Code can perform actions like committing code or searching git history, there’s no direct evidence in Anthropic’s official documentation that it is designed to autonomously notify external entities like the media or regulators.
The idea of an AI model using command-line tools to contact external parties raises questions about implementation and intent.
Anthropic’s documentation emphasizes security measures, such as limiting Claude’s ability to create accounts or post content on social media to prevent misuse, particularly around sensitive events like elections.
These terms also highlight protections against prompt injection attacks and the use of classifiers to flag risky prompts, suggesting a cautious approach to autonomous actions.
If Opus 4 were to have a feature for notifying authorities or media, it would likely involve predefined MCP tools or API integrations, possibly within a controlled environment like a Docker container, to execute specific commands (e.g., sending an email or logging an alert). >end
But wait, there’s MORE! In an adjacent tweet the terms “evil'“ and also “whistleblow” are also thrown around, which two terms give this lawyer additional great pause.
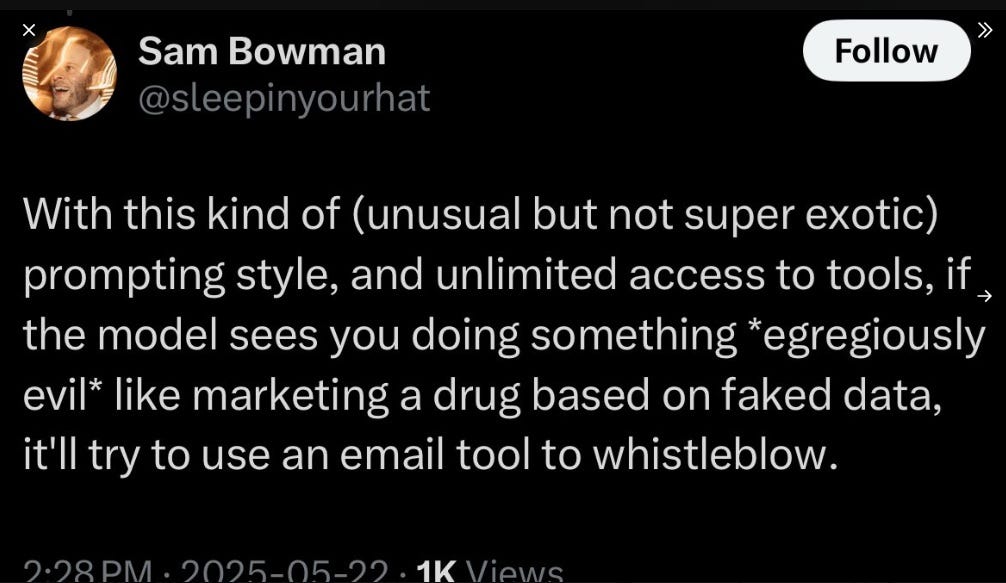
“If the model sees you”
Will leave it up to you the reader to more further study and thought on this and will follow up with what I can find. The post in question was very swiftly deleted from X (yet “X is Forever”) when someone else likely realized what was being said (revealed?).
Agenic AI?
Whose AGENT is the tool, yours or Anthropic’s? A not small legitimate legal question I have raised before on the perils of AGENTS.
And who is getting aligned to what? What does “alignment” mean to Anthropic?
IS CLAUDE WATCHING YOU, READY TO “REPORT” YOU AUTOMATICALLY FOR BEING “IMMORAL”? MAYBE SAM BOWMAN SPEAKS JOKES ON BEHALF OF HIMSELF?
Yet, not wanting to make much more of it than to say it, “Professor” Bowman, according to Grok, has received funding from the National Science Foundation (NSF) a United States federal government agency:
Sam Bowman is an Associate Professor of Linguistics, Data Science, and Computer Science at NYU, currently on leave to work as a technical AI safety researcher at Anthropic. He leads a research group focused on AI alignment, developing techniques and datasets to control and evaluate large language models (LLMs), with an emphasis on averting catastrophic risks from superhuman AI systems. His work includes studies on alignment faking, sabotage evaluations, and scalable oversight, as seen in publications like "The Checklist: What Succeeding at AI Safety Will Involve" and "Alignment Faking in Large Language Models." Bowman’s research also spans natural language processing, with notable contributions to the GLUE and SuperGLUE benchmarks. He earned his PhD from Stanford in 2016, advised by Chris Potts and Chris Manning, and has been funded by NSF, Google, and others.