


THE BIGGEST AI TARIFF YOU HAVE NEVER HEARD OF
Until AI Counsel Brought to You - Read on...


(Article includes personal notes on Project gist and more invented things)
What is the SINGLE GREATEST TARIFF HURTING AI DEVELOPMENT?
COMPUTE COST!
Compute cost represents the hidden show-stopper cost center "Auto-Tariff" Threatening U.S. AI Development and Dominance, and thereby the development of AI in the world.
In the race to lead the global artificial intelligence (AI) revolution, the United States has long held a commanding position, fueled by its technological prowess, deep pools of talent, and massive capital investments.
Yet, beneath this apparent dominance lies a silent but formidable obstacle: the staggering cost of compute in the U.S., which acts as an insidious "auto-tariff" on American AI development.
This self-imposed economic barrier—stemming from the high price of computational resources domestically—puts the U.S. AI companies (and writ global, ai development] at a significant disadvantage compared to their competitors in Asia, India, and Russia, where compute costs are roughly 5% of those in the U.S.
If this disparity persists unaddressed, the U.S. risks losing its edge in AI innovation, with emerging players like China’s DeepSeek already showcasing the consequences of this "auto-tariff" in action.
IT ALSO MEANS AN ESTOPPING OF GLOBAL AI DEVELOPMENT FOR THE REST OF THE WORLD AS MANY/MOST CAPITAL ENGINES FIRE IN THE STATES, AND WITH A MANDATE FROM THE WHITE HOUSE.
Break it Down: The Compute Cost Disparity: A 20x "Auto-Tariff"
Compute power—measured in terms of processing units like GPUs (graphics processing units), energy consumption, and data center infrastructure—is the lifeblood of AI development, and 70-90% of the carrying cost of AI applications.
Training sophisticated AI models, such as large language models (LLMs) or reasoning systems, requires vast computational resources, often costing millions or even billions of dollars.
In the U.S., these costs are (auto-matically, presently) astronomical.
For instance, estimates suggest that OpenAI spent around $100 million to train GPT-4, a figure driven by the high price of domestic compute resources, including cutting-edge Nvidia GPUs and the energy-intensive data centers that house them.
Analysts estimate that major U.S. cloud providers like Amazon, Microsoft, and Google will collectively spend $250 billion on AI infrastructure in 2025 alone, with compute costs accounting for a significant chunk of that figure.
Contrast this with Asia, India, and Russia, where compute costs are a fraction of the U.S. equivalent—approximately 5%, or a 20-fold difference.
In India, for example, cloud computing services from providers like Reliance Jio or Tata Communications offer GPU access at rates as low as $0.10 per hour, compared to $2.00 or more per hour for comparable services from U.S.-based AWS or Azure.
In Russia, domestic providers like Yandex Cloud leverage lower energy costs—electricity prices hover around $0.05 per kWh versus $0.13 per kWh in the U.S.—to deliver compute at a steep discount.
China, meanwhile, has optimized its AI ecosystem with state-subsidized infrastructure and stockpiles of Nvidia chips acquired before U.S. export controls tightened, enabling startups like DeepSeek to train models for pennies on the dollar.
DeepSeek’s V3 model, for instance, reportedly cost just $5.6 million to train, a figure that underscores the stark contrast with U.S. expenditures.
This cost differential is not a traditional tariff imposed by governments but an "auto-tariff"—a structural penalty baked into the U.S. economic and technological landscape.
It arises from high labor costs, expensive real estate for data centers, and a reliance on premium hardware, all of which inflate the price of compute far beyond what competitors overseas must pay. THIS DOES NOT COUNT PROFIT PREMIUMS!
The result? U.S. AI companies face a hidden tax that their rivals in Asia, India, and Russia simply do not, tilting the global playing field against American innovators.
The Disadvantage to U.S. AI Companies
The "auto-tariff" on compute imposes a triple threat to U.S. AI firms:
higher development costs,
slower iteration cycles, and
reduced scalability.
First, the sheer expense of training models in the U.S. forces companies to allocate massive budgets just to keep pace. For example, Anthropic, a U.S.-based AI startup, reportedly burns through tens of millions annually on compute alone, a burden that limits its ability to experiment with new architectures or scale operations as aggressively as leaner foreign competitors. Meanwhile, a company like DeepSeek can achieve comparable results—matching or exceeding GPT-4’s performance—for a fraction of the cost, freeing up capital for further innovation or market expansion.
Second, high compute costs slow down the research and development cycle. Training a single state-of-the-art model can take months and millions of dollars in the U.S., whereas lower costs abroad allow competitors to iterate more rapidly. In China, DeepSeek developed its R1 reasoning model in just two months using Nvidia H800 chips, a feat that stunned industry observers.
This agility gives non-U.S. firms a first-mover advantage, enabling them to deploy cutting-edge solutions while American companies are still crunching numbers on expensive domestic infrastructure.
Finally, scalability becomes a bottleneck. U.S. firms must charge premium prices to recoup their compute investments—OpenAI’s o1 model, for instance, costs $15 per million input tokens, compared to DeepSeek’s R1 at $0.55 per million.
This pricing gap makes U.S. AI less accessible to global users, ceding market share to cheaper alternatives. As DeepSeek’s AI assistant rocketed to the top of Apple’s U.S. App Store in January 2025, it demonstrated how cost efficiency can translate into rapid adoption, leaving pricier U.S. offerings in the dust.

The Competitive Threat: DeepSeek and Beyond
The rise of DeepSeek is a glaring warning sign that the "auto-tariff" is already eroding U.S. AI dominance.
Founded in 2023 by Liang Wenfeng, a former hedge fund manager, DeepSeek leveraged China’s low-cost compute ecosystem to produce models that rival the best from OpenAI, Google, and Anthropic. Its V3 model, trained on a modest cluster of 2,048 Nvidia H800 GPUs for under $6 million, delivers performance on par with GPT-4, while its R1 reasoning model outperforms OpenAI’s o1 on key benchmarks—at 20 to 50 times lower usage costs.
[THERE ARE RUMBLINGS OF PIRACY —- SURPRISE!]
The hyper performance of DeepSeek suddenly and widely sparked an AI (computer) market panic in January 2025, wiping $588 billion off Nvidia’s market cap in a single day as investors questioned the sustainability of U.S. tech giants’ compute-heavy strategies.
DeepSeek is not an anomaly but a harbinger.
In India, startups like Krutrim are tapping into cheap cloud resources to build vernacular AI models, targeting a billion-plus users at costs U.S. firms can’t match.
Russia’s Sberbank has deployed AI systems for banking and healthcare, powered by domestic compute infrastructure that undercuts Western prices by orders of magnitude.

Across Asia, state-backed initiatives—such as China’s 48 data exchanges and planned 100 "trusted data spaces" by 2028—further amplify the cost advantage, enabling a flood of low-cost, high-performance AI solutions.
If the U.S. fails to address this "auto-tariff," the consequences could be dire. Cheaper foreign AI could flood global markets, undercutting American firms and eroding their influence over standards, ethics, and security in AI deployment.
Worse, as compute efficiency becomes a competitive differentiator, U.S. companies may fall behind in raw capability. DeepSeek’s success suggests that innovation can thrive without the brute-force spending that has defined the U.S. approach—unless something changes, America’s AI lead could slip away.
Compute Tariff Costs Start-ups and New AI Development the Most
While the "auto-tariff" of high compute costs threatens the entire U.S. AI ecosystem, its most devastating impact falls on startups and new AI development—the very engines of innovation that have historically driven American technological leadership. Without the deep pockets of tech giants like OpenAI, Google, or Microsoft, fledgling AI companies face a cost-prohibitive landscape where the price of compute can make or break their survival. This hidden tax not only stifles creativity and experimentation but also pushes founders into debt, forces reliance on foreign alternatives, and raises a fundamental question: Why would a startup plan their business around an 80% cost center when the same resources are available for 5% elsewhere?
For AI startups, compute costs are often the single largest expense, dwarfing salaries, office space, or marketing.
Take xAI, a U.S.-based startup founded in 2023 to advance human scientific discovery.
Despite raising $6 billion in funding, its ambitious projects—like building a reasoning-focused AI—require millions in compute alone. Smaller players without such backing fare far worse.
GUYS I AM STILL TRYING TO MAKE A SALE WITH XAI! PRAY AND CALL ELON.
Consider Perplexity, an AI search startup that spent an estimated $20 million on compute in 2024 to train and run its models, relying heavily on U.S. cloud providers like AWS. For a company with $250 million in total funding, that’s a massive chunk of capital burned just to stay competitive—capital that could have gone toward hiring talent or expanding features.
The cost of demoing or iterating on a product exacerbates the problem.
Each time a startup trains a new model or showcases its tech to investors, it racks up thousands—or tens of thousands—in compute bills. For instance, a single training run on OpenAI’s API or AWS GPUs for a modest LLM can cost $50,000 to $100,000, depending on scale.
Founders like Sarah Chen, who launched an AI-driven healthcare diagnostics startup in 2024, report going into personal debt to cover these expenses. “Every demo costs me $5,000 in compute,” Chen said in a recent interview. “I’ve maxed out two credit cards just to keep pitching.”
Without a major backer like a venture capital firm or a tech titan, such costs become an insurmountable barrier, forcing many promising ideas to wither before they can bloom.
Guys this is real. CapDev. I only was half-joking when I said I invented a new venture capital funding round I call the NSR — “Negative Seed Round”. Each time I build and try; each time I test; each time I show to another; each time I (almost God forbid) release to a potential patron (who may share inside their org) I incur costs, such that I experience reticence to show my wares except in the case of the only most serious.
Recall mine is not a big model. It is many many (many) small bespoke models (slm).
Ha ha. I say “I have already worked with some of the top firms, have shown them new models, actually have invested in them (ha!).”
Also another novelty, I am now not FUND raising but rather COMPUTE RAISING! Hi Elon, I’m whispering into your robot ear.

This financial strain drives startups to seek alternatives outside the U.S., where the "auto-tariff" doesn’t apply.
Indian cloud provider E2E Networks, for example, offers GPU access at $0.12 per hour—compared to $2.50 per hour from U.S.-based providers—prompting startups like San Francisco-based Nexlify to shift their training workloads to Hyderabad.
Similarly, Russian firm Selectel provides compute at rates as low as $0.08 per hour, attracting U.S. founders willing to navigate geopolitical risks for cost savings.
Even DeepSeek’s rise has inspired copycats: a New York-based AI gaming startup recently partnered with a Chinese data center to train its models for $200,000, a job that would have cost $4 million stateside. “At 5% of the cost, it’s a no-brainer,” the founder told TechCrunch anonymously, citing the need to stay under the radar of U.S. regulators.
The economics simply don’t add up for U.S.-based startups tethered to domestic compute. If 80% of a company’s budget is consumed by compute—a reality for many early-stage AI ventures—there’s little left for growth or innovation. Why would an entrepreneur build a business plan around such a crippling cost center when competitors in Asia, India, or Russia can access the same power for a fraction of the price? This disparity not only disadvantages U.S. startups but also risks a brain drain of talent and ideas. Founders are increasingly eyeing overseas hubs like Bangalore or Shenzhen, where low compute costs enable rapid prototyping and scaling without breaking the bank.
The "auto-tariff" of compute costs is choking the next generation of AI pioneers. Without intervention—whether through subsidies, shared compute resources, or efficiency breakthroughs—startups will continue to bleed cash, go bust, or flee abroad. The U.S. cannot afford to let its AI future hinge on a handful of well-funded giants while its scrappy innovators drown under a self-imposed burden. If the compute tariff isn’t dismantled, the startups that could define tomorrow’s AI landscape may find their home not in Silicon Valley, but in cities where 5% is the norm, not 80%.

[-AIC Prediction: given the political dynamics in America (read: migration issue) the next three years will see a steep rise in a class of founders few know about (but I do since my experience in BPO/Indian FDI since 2004) — the so-called “Returnees” these are Indian founders who went to the USA for work or to found a company then decided to return home to India to found again there in their original home. READ ABOUT THIS IN THE PAPER IN THREE MONTHS, HEAR IT FROM AIC TODAY, “Hot ‘New’ Trend: Indian Returnee AI Megafounders”…hey many Americans will join them!]
Here is a good article on what’s known as the “reverse brain drain” from an Indian perspective on returnees ECONOMIC TIMES (of India)
SOME CHARTING
[ChatGPT produced this for me on 4.7.25]
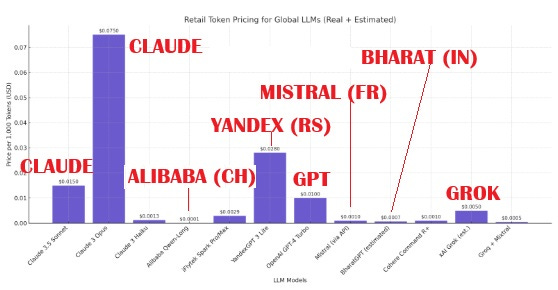
[Grok 3 produced this for me on 4.7.25]

ANDAND
Sorry to go on for soo long esp for a MONDAY. Follow me on X @AiCounselDallas Will do future article as compute also is reconfiguring CORPORATE LAW and CORPORATE STRUCTURE before our very eyes with something I am calling alternatively the “Tik Tok Model” or the OO Companies, or OREO Companies (Onshore Resident, Executing Offshore), or OI Companies, maybe OREO is the best (yum!)
